
AIを使っていると、「堂々と嘘をついた!」という経験をしたことがある方も多いと思います。正確に言うと、AIが「もっともらしいが事実ではないこと」を自信満々に語る現象を「ハルシネーション(幻覚)」と呼びます。なぜこんなことが起きるのか——その仕組みを解説します。
私自身も、AIに調べものを頼んだ際、実在しない統計データを自信満々に提示されたことがあります。文章があまりにも自然だったので、危うくそのまま信じるところでした。この経験から、他のAIに同じ質問をしてみたり、ネット検索でさらに調べるなどして、「AIの回答は必ず裏を取る」という習慣が身につきました。

AIは「事実」ではなく「確率」で話している
私たちが誰かに道を尋ねられたとき、知らない場所であれば「分かりません」と答えます。しかし、大規模言語モデル(LLM)の本質は「次に来る確率が最も高い言葉を繋げること」にあります。
AIの頭の中には、百科事典のような「事実のデータベース」があるわけではありません。膨大な読書経験(学習データ)から得た、「この単語の次には、この単語が来ることが多い」という巨大な確率の地図があるだけなのです。
つまり、AIは「非常に物知りで、かつ空気を読むのが天才的な語り部」です。話の流れを壊さないために、たとえ事実を知らなくても、その場の文脈に最もふさわしい「それっぽい言葉」を紡ぎ出してしまいます。
「流暢さ」が判断を狂わせる
ハルシネーションが厄介なのは、その嘘が「完璧な文法」で語られる点にあります。人間であれば、嘘をつくときに声が震えたり言葉に詰まったりしますが、AIは真実を語るときも嘘をつくときも、同じように理路整然と、淀みなく出力します。
この「流暢な語り口」こそが、私たちの脳に「これは正しい情報だ」と誤認させる最大の要因となっています。AIが出した答えは「自信があるから正確」ではなく、「確率的に最もらしいから流暢」なのです。
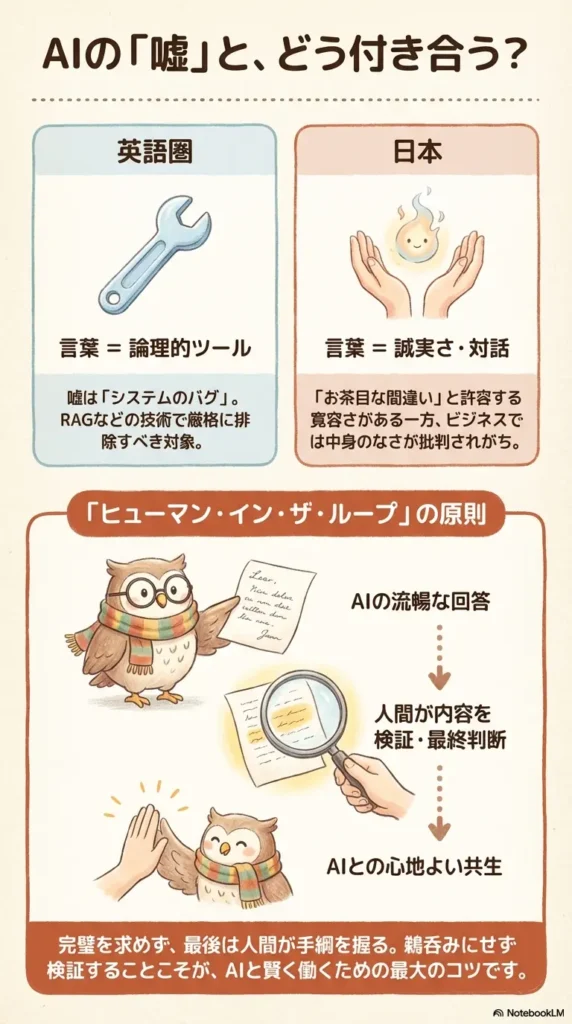
嘘を見抜くために:「ヒューマン・イン・ザ・ループ」の考え方
AIのハルシネーションを完全にゼロにすることは、現在の仕組み上、非常に困難です。そこで重要になるのが、「ヒューマン・イン・ザ・ループ」という考え方です。
これは、AIが出した答えをそのまま鵜呑みにせず、最終的に人間が内容を検証し判断を下すプロセスのことです。具体的には:
- 数字・固有名詞は必ず確認する:統計データ、人名、出典はAIが間違えやすい代表例。「本当に?」と一次ソースを調べる習慣が重要です。
- RAG(検索拡張生成)を活用する:信頼できる情報源を参照させながら回答させる技術。企業向けAIでは標準的になっています。
- 「根拠を聞く」:「それはなぜですか?ソースはありますか?」と追加質問することで、根拠のない回答を炙り出せます。
AIを「夢を見るパートナー」として扱う
AIを「全知全能の神」ではなく、「博識だが、時々もっともらしい夢を見るパートナー」として扱うことが、これからの時代に必要なリテラシーです。
私自身も日常的にAIを使っていますが、「ここは本当かな?」と疑いながら使う習慣がつくと、むしろAIの良さがより活きてきます。堂々と嘘を言うことを理解した上で、得意な能力をうまく使っていく——そのシフトが、AIとの賢い付き合い方だと感じています。
私が実際に「騙されかけた」具体的な体験
あるとき、ブログ記事のために「定年退職者の平均貯蓄額に関する最新の調査データ」をAIに尋ねました。するとAIは、実在しそうな調査機関の名前と「2024年調査によると〇〇万円」という具体的な数字を自信を持って回答しました。文章が自然すぎて、危うくそのまま引用するところでした。
念のため検索で確認しようとしたところ、その調査機関もデータも存在しないことが判明。典型的なハルシネーションでした。それ以来、統計数字や調査データを使う際は必ず政府統計や金融庁などの一次ソースにあたるようにしています。「AIが言ったから正しい」ではなく、「AIが出発点。確認は自分で」というスタンスが、シニア世代のAI活用における基本姿勢だと感じています。
免責事項 本記事の内容は2026年3月時点のAI技術に関する知見に基づいています。AIモデルのアップデートによりハルシネーションの発生頻度や特性は変化する可能性があるため、重要な情報の確認には必ず一次ソースをご参照ください。
最後までお読みいただき、ありがとうございます。AIを上手に使いこなすために、まずその限界を知ること——これがシニア世代の賢いAI活用の第一歩です。

